Zusammenfassung
Der Beitrag gibt eine Übersicht Kern-Technologien der digitalen Bildverarbeitung wie digitale Bildformate, Video-Kompression und Video-Streaming. Dabei werden die Vor- und Nachteile der Verfahren für den Einsatz im professionellen Umfeld z. B. der Fertigungsautomation, Medizintechnik und Überwachungstechnik vorgestellt. Der Beitrag wendet sich an Entscheider, die den Einsatz von Video in professionellen Systeme planen und die sich einen Hintergrund zur Technologie und Terminologie verschaffen wollen.
Werkzeuge/Technolgie
Bildverarbeitung: Farbräume, Farbabtastung
Codecs: JPEG, MPEG, H.264, Einzel- und Differenzbild-Kompression
Transport: RTP/RTSP, HTTP-Push, HTTP-Pull
Inhaltsverzeichnis
Einleitung
Kompression und Datenreduktion
Videoformate
Streaming-Verfahren
Übersicht zu Kompressions- und Streaming-Verfahren in der professionellen Video-Verarbeitung
Einleitung
Die heutige Vielfalt der Anwendungen digitaler Videotechnik ist hauptsächlich durch den Einsatz hocheffizienter Kompressions-, Übertragungs- und Speichertechnologien möglich geworden. Im Folgenden soll ein Überblick über die wichtigsten Kompressions- und Streaming-Technologien und deren Besonderheiten bei der Anwendung außerhalb des Multimedia-Umfeldes betrachtet werden. Neben den klassischen Multimedia-Anwendungen wie TV und DVD findet Video heute zunehmend einen breiten Einsatz:- in industriellen Systemen zur Prozess-Beobachtung und Optimierung
- im der Medizintechnik
- in Sicherheitssystemen und Videoüberwachungsanlagen
- im Machine Vision Umfeld gekoppelt mit Bildverarbeitungsverfahren zur Analyse von Bildinhalten
- in der Verkehrsüberwachung zur Analyse von Verkehrssituationen und Staubildung
- Im industriellen Einsatz spielt die Latenz - also die Verzögerungen von Bildaufnahme bis zur Bild-Präsentation oder Auswertung - oftmals eine wichtige Rolle.
- Andere Einsatzfälle erfordern die zeitgleiche Kompression und Übertragung einer Vielzahl von Kanälen mit teilweise Auflösungen bis in den Megapixel Bereich. Hier spielt die Performanz und die Kosten von Multikanal Encoding und Streaming Technologien eine wesentliche Rolle.
- Oftmals besteht die Anforderung nach der Verknüpfung von Bildinformationen mit Prozessdaten - z. B. Messwerten in industriellen Prozessen oder aus der Gebäudeleittechnik. Diese Daten können entweder als Overlay direkt in die Bilder eingeblendet werden oder getrennt in Datenbanken gespeichert und mit den Bilddaten verknüpft werden. Hier spielt der Aspekt Bildverarbeitung in der Übertragungskette von Bilddaten eine wichtige Rolle.
Kompression und Datenreduktion
Die Digitalisierung von Videoquellen erfordert die Übertragung, Verarbeitung und Speicherung großer Datenmengen. Betrachten wir als Beispiel die Digitalisierung einer D1 PAL Videoquelle:- Auflösung 720 x 576 Pixel, 3 Farben RGB, 8 Bit / Farbe, 24 Bit / Pixel = 1.215 kB, 9.720 KBit pro Bild
- 25 Bilder pro Sekunde = 29,7 MB/s, 237,3 MBit/s
- Speicherbedarf für eine Stunde: ca. 104 GB
- Aufzeichnungstiefe 1 TB Festplatte: ca. 10 Stunden
- Farbraumtransformation und Chroma-Subsampling
- DCT-Transformation und Quantisierung
- Differenzbilderkodierung und Motion Compensation
Farbraumtransformation und Chroma-Subsampling
Wie bei den meisten Kompressionsverfahren nutzt man auch hier eine Schwäche unseres Sehsystems aus: Das menschliche Auge nimmt Helligkeitsunterschiede wesentlich stärker als Farbunterschiede wahr. Betrachten wir das folgende Bild:






- 4:4:4 - es findet kein Subsampling statt
- 4:2:2 - die horizontale Auflösung der U/Cb- und V/Cr-Kanäle wird halbiert
- 4:2:0 - sowohl die horizontale als auch die vertikale Auflösung der Farbkanäle werden halbiert

DCT-Transformation und Quantisierung
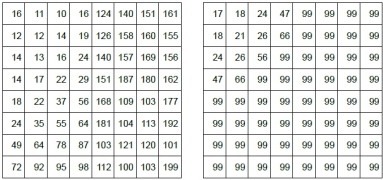
Ein weiteres Verfahren zur Datenreduktion ist die Diskrete Kosinustransformation (DCT) mit anschließender Quantisierung. Bei diesem Verfahren zerlegt man das Bild zuerst in einzelne Blöcke (meist 8x8 Pixel, hier der Ausschnitt mit dem linken Außenspiegels des roten Autos). Die Blöcke werden nun mittels DCT aus dem Ortsbereich (ortsbezogene Helligkeitsstufen) in den Frequenzbereich transformiert. Dabei wird das Bild als lineare Kombination der einzelnen Spektralkomponenten (rechtes Bild, hier DCT-II mit N1=N2=8) dargestellt. Die gewonnenen Spektralkoeffizienten werden anschließend durch den Quantisierungsfaktor dividiert und gerundet:


- links - Ausgangsblock des Bildes, Helligkeitsstufen
- mitte - Ergebnis der DCT-Transformation, Spektralkoeffizienten
- rechts - Ergebnis der Quantisierung mit dem globalen Quantisierungsfaktor 10

Differenzbilderkodierung und Motion Compensation
Differenzbilderkodierung ist eine Variante der Delta-Kodierung, bei der nicht die Daten selbst, sondern die Differenz (Delta) zu bestimmten Referenzen gespeichert werden. Wenn die Daten stark korrelieren, sind diese Differenzen klein und man erreicht dadurch eine große Datenreduktion. In einer Videosequenz unterscheiden sich die benachbarten Frames nur unwesentlich. Betrachten wir folgende Bilder einer Verkehrsüberwachungskamera:



![]()


- Bilder 1 bis 3 - 108 kB
- Differenzbild 2 - 56 kB
- Differenzbild 3 - 73 kB
- Block Motion Compensation (BMC)
- Global Motion Compensation (GMC)
Unkomprimierte Videodaten
In einigen Anwenderszenarien sind unkomprimierte digitale Videodaten notwendig. Dies wird z.B. wegen der nachgelagerten Videokompression, geringer Latenz oder höchstmöglicher Videoqualität verlangt. In diesem Fall verwendet man meist das Serial Digital Interface (SDI), das in verschiedenen Varianten sowohl für SD- als auch für HD-Quellen existiert. Die Übertragungsraten bewegen sich im Bereich von 270 MBit/s bis ca. 3 Gbit/s pro Kanal.Videoformate
Grundlagen
Im Abschnitt 1.3. haben wir gesehen, dass die Differenzbilderkodierung und Motion Compensation einen wesentlichen Teil der Datenreduktion bei Videosequenzen bilden. Im Hinblick auf die Bewegungsvorhersage können wir folgende Arten von Videoframes unterscheiden:- I-Frame (intra coded frame)
- P-Frame (predictive coded frame)
- B-Frame (bidirectionally predictive coded frame)
I-Frames
![]()
- Direkter Zugriff auf die einzelnen Frames: Um I10 zu dekodieren, benötigt man lediglich diesen Frame
- Kommt es zu Übertagungsfehlern, wird nur der betroffene Frame beeinflusst, es hat keine Auswirkungen auf die anderen Frames der Videosequenz
- Kurze Latenzen: die Bilder können sofort übertragen werden
- Schlechte Kompression, da keine Differenzbilderkodierung verwendet wird
P-Frames
![]()
- Bessere Kompression (ca. 30 - 40 % der Größe der vergleichbaren I-Frames)
- Kurze Latenzen: die Bilder können sofort übertragen werden (ähnlich wie bei "I-Frame only"- Videosequenzen).
- Kein direkter Zugriff auf die einzelne Frames: Um P10 zu dekodieren, benötigt man alle vorhergehenden Frames, also von I1 bis P9.
- Kommt es zu Übertagungsfehlern, werden nun alle nachfolgenden Frames beeinflusst, diese können nicht mehr dekodiert werden.
B-Frames
![]()
![]()
- Sehr gute Kompression (ca. 5 - 10 % der Größe der vergleichbaren I-Frames)
- Kommt es zu Übertagungsfehlern, wird nur der betroffene Frame beeinflusst, es hat keine Auswirkungen auf die anderen Frames der Videosequenz
- Kein direkter Zugriff auf die einzelnen Frames: Um B10 zu dekodieren, benötigt man alle vorhergehenden I- und P-Frames, also I1, P2, P9 und P13.
- Große Latenzen: bei der Kodierung müssen einige Frames (in unserem Beispiel 4 Frames) abgewartet werden.
GOP
Die Group Of Pictures (GOP) ist eine Gruppe der Bilder, die in Abhängigkeit zueinander kodiert sind:
![]()
- Ein Intra-Frame befindet sich normalerweise nur am Anfang der GOP. Solange es nicht empfangen wurde, kann nichts dekodiert werden.
- Der Sequenz-Header, der die wesentlichen Bildparameter wie u.a. Breite und Höhe enthält, wird meist nur am Anfang der GOP übertragen. Damit muss der Dekoder den Anfang der GOP abwarten, bevor er die Parameter der Videosequenz erfahren kann.
M-JPEG
Motion JPEG (M-JPEG) ist ein Videoformat, bei dem jeder einzelne Frame in der Videosequenz als unabhängiges JPEG-Bild kodiert ist. Die Videosequenz entspricht daher einer Folge der I-Frames. Das M-JPEG Format zeichnet sich durch folgende Merkmale aus:- Moderate Kompression: Die Kompressionsrate beträgt etwa 10 - 15 % des Originalformates.
- Einfache Implementierung mit Standardbibliotheken
- Gute Qualität auch bei schneller Bewegung
- Keine großen Anforderungen an die Hardware (Speicher und CPU)
- Direkte Unterstützung in vielen Client-Anwendungen (u.a. in Firefox oder Safari/Webkit)
- Keine Verfahrens-bedingte Latenz
- Vergleichsweise geringe Rechenlast
MPEG-1/2
Moving Picture Experts Group (MPEG) ist eine von der ISO eingesetzte Expertengruppe, die sich um die Standardisierung der Verfahren für die Videokompression kümmert. Diese Gruppe hat eine Reihe an Videoformaten entwickelt und standardisiert, die bekanntesten sind MPEG-1, MPEG-2 und MPEG-4. MPEG-1 und MPEG-2 sind die ersten Kompressionsformate der MPEG-Gruppe, die Ende 1980 - Anfang 1990 entstanden sind. Diese Formate enthalten alle besprochenen Kompressionsmitteln: Chroma-Subsampling, Differenzbilderkodierung mit Motion Compensation, etc. Das Format sieht eine Menge von Compression-Features vor, die nicht von allen Dekodern komplett unterstützt werden können. Aus diesem Grund hat man das Konzept der Profile und Level eingeführt:- Profile definiert eine Untermenge der Features (hier sind nur einiges aufgezahlt):
- SP (Simple Profile): keine B-Frames, kein Interlace
- MP (Main Profile): kein 4:2:2 Subsampling, nur 4:2:0, ...
- HP (High Profile): mehrere Streams (Scalability), hohere Prazision, ...
- Level definiert maximale technische Parameter wie Auflosung, Durchsatz, etc.
- SL (Simple Level): 352x288 @ 25 fps, 4 Mbit/s
- ML (Main Level): 720x576 @ 25 fps, 15 Mbit/s
- HL (High Level): 1.920x1.152 @ 30 fps, 80 MBit/s
MPEG-4, H.264
MPEG-4 war der nächste Standard der MPEG-Gruppe und wurde bereits 1998 veröffentlicht. Es enthält die meisten Funktionen aus MPEG-1/2 und vergleichbaren Formaten und erweitert diese um einige neue Funktionen: VRML für 3D-Objekte, Objektorientierte Komposition der Dateien, DRM, etc. Es ist also wesentlich mehr als nur ein neues Videokompressionsverfahren, es ist eher ein ganzes Framework, was allerdings für unsere Betrachtungen nicht relevant ist. MPEG-4 Standard besteht aus mehren Teilen. Für uns sind zwei Teile relevant:- Teil 2: Advanced Simple Profile (ASP)
MPEG-4 part 2 ASP ist das Format, das man umgangssprachlich als MPEG-4 Format versteht. Aus Sicht der Videokompression hat es nur wenige Vorteile im Vergleich zu MPEG-2 und bietet deswegen nur eine leicht bessere Kompressionsrate. In diese Kategorie fallen bekannte Codecs wie DivX ;-) oder XviD. - Teil 10: Advanced Video Coding (AVC)
MPEG-4 part 10 AVC ist das Format, das besser unter dem Namen H.264 bekannt ist. Hier wurden viele neue Techniken eingesetzt, z.B. DCT-ähnliche Integertransformation ohne Rundungsfehler, erweiterte Entropiekodierung CAVLC bzw. CABAC, Intra Prediction, etc. Mit diesen Techniken erreicht man eine Kompressionsrate von unter 50 % bzgl. der MPEG-2 Kompression.
- Profile
- BP (Baseline Profile) und CBP (Constrained Baseline Profile): keine B-Slices, kein CABAC, ...
- MP (Main Profile): wie BP aber mit B-Slices, mit CABAC, mit Interlacing, ...
- HP (High Profile): wie MP aber mit 8x8-Transformation, mit Quantization Scaling Matrices, ...
- Level
- 1: maximal 176x144 @ 15 fps, 64 kBit/s
- 2: maximal 352x288 @ 30 fps, 2 MBit/s
- 3: maximal 720x576 @ 25 fps, 10 Mbit/s
- 3.1: maximal 1280x720 @ 30 fps, 14 Mbit/s
- 3.2: maximal 1280x720 @ 60 fps, 20 Mbit/s
- 4: maximal 1920x1080 @ 30 fps, 20 Mbit/s
- 4.1: maximal 1920x1080 @ 30 fps, 50 Mbit/s
- 4.2: maximal 1920x1080 @ 60 fps, 50 Mbit/s
- 5: maximal 3672x1536 @ 25 fps, 135 Mbit/s
- 5.1: maximal 4096x2160 @ 60 fps, 240 Mbit/s
Zusammenfassung
Die Kompressionsraten der einzelnen Videoformate hängen wesentlich vom Bildinhalt ab, so benötigen scharfe Kanten und schnelle Bewegungen größere Mengen an Daten als weiche Übergänge und statische Motive. Als grobe Richtwerte für eine D1-Kamera bei 25 fps können wir folgende Zahlen verwenden:- Unkomprimiert 240 Mbit/s
- M-JPEG 20 Mbit/s
- MPEG-2 4 Mbit/s
- H.264 1 Mbit/s
- H.261 - ist der Vorläufer von MPEG-1
- H.262 - ist identisch mit MPEG-2
- H.263 - ist der Vorläufer von MPEG-4 ASP
- H.264 - ist identisch mit MPEG-4 AVC
Streaming-Verfahren
Grundlagen
Die Kommunikation in Rechnernetzen erfolgt nach bestimmten Regeln. Diese nennt man Netzwerkprotokolle. Bei der Betrachtung und Zuordnung der einzelnen Protokolle haben sich TCP/IP- und ISO/OSI-Referenzmodelle hilfreich erwiesen:
| OSI-Schicht | TCP/IP-Schicht | Protokolle |
| Anwendungen, Darstellung, Sitzung | Anwendungen | HTTP, FTP, RTSP, RTP |
| Transport | Transport | TCP, UDP |
| Vermittlung | Internet | IP, ARP, ICMP |
| Sicherung, Bitübertragung | Netzzugang | Ethernet, FDDI |
IP
Das Internet Protocol (IP) definiert den Aufbau und die Struktur von IP-Adressen sowie die Mechanismen, wie Pakete von einer Sender-IP-Adresse zu einer Empfänger-IP-Adresse übertragen werden können.
TCP
Das Transport Control Protocol (TCP) ist für die Paketierung der Anwendungsdaten zuständig und hat insbesondere folgende Eigenschaften:
- Zuverlässig: Alle gesendeten Daten kommen vollständig und in richtiger Reihenfolge an, es gibt keine Duplikate.
- Verbindungsorientiert: Zwischen Sender und Empfänger wird eine Nachrichtenverbindung aufgebaut und aufrechterhalten.
Das Protokoll implementiert einen Bestätigungsmechanismus, mit dem der Empfang der Daten quittiert werden muss. Beim Auftreten von Störungen kümmert sich TCP um die Wiederholung der Übertragung.
Die einzelnen Pakete können auf dem Weg vom Sender zum Empfänger verschiedene Wege nehmen, sodass sich die Reihenfolge der Pakete beim Empfang von der Reihenfolge der Pakete beim Senden unterscheiden kann. Es ist also auch die Aufgabe von TCP, diese Pakete in die richtige Reihenfolge zu bringen und mögliche Duplikate zu entfernen.
Da zwischen Sender und Empfänger eine Nachrichtenverbindung aufgebaut und gehalten wird, kann der Ausfall eines der Kommunikationspartner erkannt und entsprechend reagiert werden.
UDP
Das User Datagram Protocol (UDP) ist ein minimalistisches verbindungsloses Netzwerkprotokoll. UDP ist somit nur für die Adressierung zuständig und bildet in etwa das Gegenstück zu TCP. Das Protokoll wird in Anwendungen genutzt, die keine Übertragungssicherheit erfordern.
Ein typisches Beispiel dafür ist die Übertragung von Live-Bildern. Wenn hier ein Paket verloren geht, ist seine Wiederholung unerwünscht, da es dadurch zu Verzögerungen bei der Wiedergabe kommt. Es ist hier günstiger das Paket zu verwerfen und mit dem nächsten Paket fortzufahren.
Anwendungsprotokolle
Die Anwendungsschicht des OSI- bzw. TCP/IP-Modells erfasst alle Protokolle, die direkt mit den Anwendungsprogrammen arbeiten. Diese Protokolle bauen auf die darunterliegende Transportschicht auf. So basiert HTTP auf TCP, während für RTSP sowohl TCP als auch UDP in Frage kommt.
Die Entscheidung für TCP oder für UDP hängt zum großen Teil von Zuverlässigkeitsanforderungen der Anwendung ab.
HTTP
Das Hypertext Transfer Protocol (HTTP) ist ein Netzwerkprotokoll für die Übertragung von Daten. Es wird hauptsächlich für die Datenübertragung im World Wide Web (WWW) eingesetzt, beschränkt sich aber nicht darauf.
HTTP ist ein zustandsloses Protokoll. Die Informationen aus früheren Anforderungen gehen verloren. Werden diese Informationen gebraucht (z.B. Login-Daten für die Authentifizierung), so muss sich die Anwendung selbst darum kümmern.
Die Kommunikation zwischen Client und Server erfolgt auf folgende Art und Weise:
Der Client möchte eine Datei laden und stellt eine Anfrage:
GET /image HTTP/1.0
Host: 192.168.100.1
Die einzelnen Zeilen werden mit CR+LF-Zeichen abgeschlossen, die Anfrage mit den zusätzlichen CR+LFZeichen. Der Server verarbeitet die Anfrage und antwortet mit den Daten:
HTTP/1.0 200 OK
Content-Length: (Größe des Bildes in Byte)
Connection: close
Content-Type: image/jpeg
(leere Zeile)
Daten - JPEG-Bild
Aktuell werden zwei Versionen des HTTP-Protokolls verwendet: HTTP/1.0 und HTTP/1.1. Bei der ersten Variante muss vor jeder Anfrage eine neue TCP-Verbindung aufgebaut werden und nach der Übertragung der Antwort wieder geschlossen werden. Bei einer HTTP/1.1-Verbindung kann man mit einem zusätzlichen Header-Eintrag Keep-Alive eine persistente Verbindung aufbauen, was die Kommunikationsgeschwindigkeit erhöht:

Das HTTP-Protokoll wird im professionellen Umfeld oft eingesetzt. Zum einen verwendet man dieses Protokoll, um mit Hilfe eines Web-Browsers die IP-Kameras zu parametrieren, zum anderen um auf die Bilder der Kamera zuzugreifen. Für den Zugriff auf die Bilder stehen zwei prinzipielle Möglichkeiten:
- Pull: die Bilder werden nur auf Anforderung übertragen
- Push: der Client baut eine Verbindung zum Server auf, der diese Verbindung nutzt und die Bilder ohne weitere Anforderungen an den Client zurückschickt.
HTTP-Pull
Bei diesem Verfahren werden die Bilder einzeln abgeholt. Für jedes Bild wird eine entsprechende Anfrage gestellt, die vom Server beantwortet wird, anschließend wiederholt man das Ganze:

- einfach zu implementieren
- weit verbreitet (wird von jedem Browser unterstützt)
- große Latenzen
- niedrige Kommunikationsgeschwindigkeit
HTTP-Push
Bei diesem Verfahren wird zuerst ein Verbindungskanal aufgebaut. Der Server bestätigt es, anschließend sendet er die einzelnen Bilder ohne weitere Aufforderungen:

- kurze Latenzen
- hohe Kommunikationsgeschwindigkeit
- wird nicht von allen Anwendungen unterstützt
Firefox und Safari unterstützen es, Internet Explorer dagegen nicht.
RTSP/RTP/RTCP
Das HTTP-Protokoll ist dateibasiert und eignet sich so schlecht für eine Echtzeit- oder Live-Übertragung der Videostreams. Deshalb wurden Ende 1990 eine Reihe von Netzwerkprotokollen entwickelt, die diese Lücke schließen sollten. Die wichtigsten Protokolle in diesem Bereich sind RTSP und RTP.RTSP
Das RealTime Streaming Protocol (RTSP) ist ein Netzwerkprotokoll, das explizit für die Steuerung der Video- und Audioübertragung entwickelt wurde. Auch wenn es der Name suggeriert, so werden über das Protokoll selbst keine Videodaten übertragen, dafür verwendet man RTP. Das RTSP-Protokoll dient hauptsächlich der Steuerung der Wiedergabe.
RTP
Das Real-Time Transport Protocol (RTP) ist ein Netzwerkprotokoll für die Übertragung von Multimedia-Inhalten (z.B. Videostreams). RTP ist ein paketbasiertes Protokoll. Diese Pakete enthalten sowohl die Nutzdaten (z.B. Videoframes) als auch die Informationen für die Echtzeit-Wiedergabe (z.B. Zeitstempel).
Das Zusammenspiel zwischen RTSP und RTP wird im folgenden Diagramm deutlich:

Mittels RTSP werden die Parameter des Videostreams abgefragt (welches Videoformat, mit oder ohne Audio, etc.) und eine neue Session erzeugt. Dabei werden auch die Übertragungsparameter ausgehandelt (TCP oder UDP, Portbereiche, etc.). Mit PLAY wird der Videostream gestartet. Jetzt sendet der Server die einzelnen Videopakete über das RTP-Protokoll an die vorher vereinbarten Ports. Mit einem TEARDOWN auf der RTSPSchnittstelle wird die Übertragung der Daten beendet.
Das RTP-Protokoll bietet keinen Rückkanal vom Empfänger der Bilder zum Sender. Dafür ist das RealTime Control Protocol (RTCP) definiert. Dieses Protokoll ist optional und wird zum Aushandeln und Sicherstellen der Quality Of Service (QoS)-Parametern verwendet.
Weitere Verfahren
Der Bereich des Videostreaming ist sehr dynamisch. Viele Protokolle und Standards verschwinden, ohne in der Praxis Spuren zu hinterlassen, oder werden durch Nachfolgestandards ersetzt. Durch die verstärkte Verbreitung der mobilen Endgeräte gewinnen vor allem die Techniken an Bedeutung, die browserbasierte Lösungen ohne Einsatz von Spezialsoftware anbieten.
In diesem Abschnitt soll nur eine kleine Auswahl an Standards präsentiert werden, die in der nächsten Zeit eine größere Rolle im professionellen Einsatz spielen könnten.
ONVIF
Das Open Network Video Interface Forum (ONVIF) ist ein offenes Industrieforum mit dem Ziel der Entwicklung eines Standards für die IP-Kameras. Im Wesentlichen bietet dieser Standard eine einheitliche Schnittstelle für die Konfiguration und die Steuerung der IP-Kameras. Bei der Übertragung der Bilder wird auf bereits etablierte Standards wie RTP zurückgegriffen.
Es ist bereits jetzt abzusehen, dass der Großteil der IP-Kamera-Hersteller diesen Standard unterstützen werden.
HTML5 Video
Die Hypertext Markup Language (HTML) ist eine Seitenbeschreibungssprache. Die HTML-Dokumente bilden die Grundlage des WWW. Mit HTML5 werden nun auch Elemente für Video- und Audio-Objekte standardisiert. Die Steuerung der Wiedergabe erfolgt mittels JavaScript. Die Übertragung der Daten erfolgt mittels HTTP/1.1-Protokoll. Dabei wird das Video in kleine Segmente zerlegt und stückchenweise als Partial Content zurückgeliefert.
Leider besteht noch keine Einigkeit bzgl. der unterstützten Videoformate. Diskutiert werden Theora, H.264 und VP8/WebM, weswegen es noch kein Format gibt, das von allen gängigen Browsern unterstützt wird.
WebRTC
Der Web Real-Time Communication (WebRTC) ist ein noch in der Entwicklung befindlicher Standard für die Echtzeitkommunikation innerhalb eines Web-Browsers. Das Framework basiert auf HTML5 und JavaScript. Die Übertragung der Bilder erfolgt über RTP.
Noch gibt es Unklarheiten bzgl. der zu verwendenden Videocodecs. Ebenfalls ist noch unklar, ob Microsoft mit CU-RTC eine Alternative etablieren und durchsetzen kann.